
Como Lidar com 10.000 Transações por Segundo em um App NestJS
Recentemente li esse post do Sam no X:
Quando seu app começa a escalar, você inevitavelmente se depara com essa pergunta.
Neste post, vou te mostrar como eu faria utilizando o Nestjs que é o framework que mais utilizo na prática, dividindo em decisões técnicas claras.
1. Fastify para performance
O NestJS por padrão usa o Express, mas podemos trocar para o Fastify, que é muito mais rápido. Um dos motivos é provavelmente o uso do fast-json-stringfy, que é significantemente mais rápido que o json.stringfy para payloads pequenos. Outro motivo é que o Fastify também segue recomendações relacionadas ao gerenciamento de conexões com o banco de dados, à manutenção de recursos compartilhados e à manutenção de um pool de conexões eficiente para o servidor de banco de dados.
O ganho de performance aqui já começa a te economizar milhares de requisições por segundo.
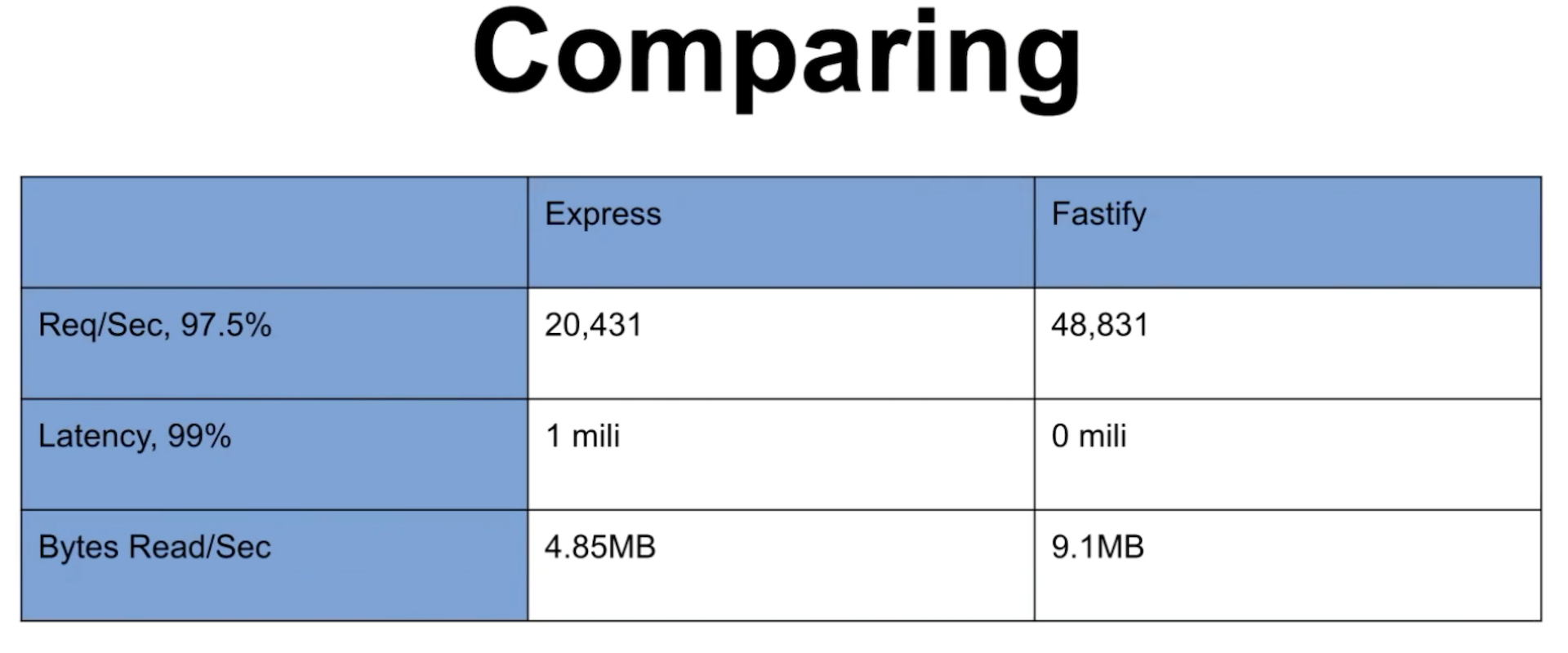
(fonte https://thenewstack.io/a-showdown-between-express-js-and-fastify-web-app-frameworks/)
2. Escalando a aplicação
Node é single-threaded. Para lidar com milhares de requisições, você precisa usar todos os núcleos da máquina. Com Kubernetes você pode criar múltiplos pods do seu app e escale com base em CPU/memória.
Podemos ir um pouco além com uma escala horizontal. Ao contrário da escala vertical, que depende do aumento de recursos computacionais em uma única máquina (CPU, memória, I/O), a escala horizontal distribui a carga entre diversas unidades homogêneas, permitindo maior tolerância a falhas, elasticidade e paralelismo. Escalando horizontalmente, cada instância é responsável por uma fração do tráfego ou da carga total, geralmente por meio de um mecanismo de balanceamento de carga.
3. Separe leitura de escrita (CQRS)
Misturar GET, POST e PUT na mesma camada de banco é receita pra gargalo. Use o pattern CQRS (Command Query Responsibility Segregation):
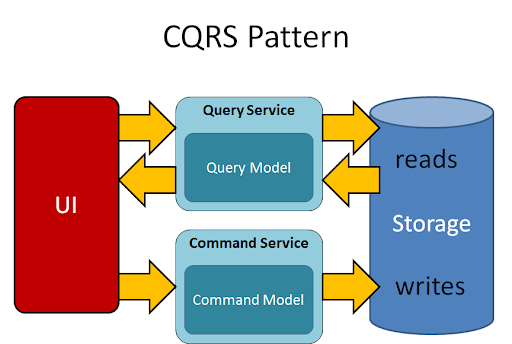
Leituras vão para réplicas do banco ou Redis.
Escritas vão para uma fila de processamento assíncrono (Kafka, Bull, etc).
Isso evita lock de escrita e permite escalar leitura de forma independente.
4. Redis para cache e filas
Para leitura: cacheie os dados mais acessados com Redis. TTL curto, invalidação quando necessário.
Para escrita/modificação: use Bull (ou Kafka) para enfileirar e processar com workers.
5. Um banco preparado pra carga real
Se estiver com PostgreSQL:
Use read replicas para GETs
Faça connection pooling
Monitore locks e índices
6. Monitoramento
Use:
Prometheus + Grafana para métricas
Winston ou Pino para logs estruturados
Jaeger ou OpenTelemetry para tracing
Você só escala o que consegue medir.
Tentei abordar algumas decisões mais comuns, mas obviamente não é uma receita de bolo, cada decisão vai depender do contexto e de milhares de variáveis. É importante considerar as decisões mais viáveis antes de tomar uma decisão